OCR(광학 문자 인식)
OCR 은 optical character recognition의 약자로, 한국어로 광학 문자 인식을 의미한다.
보통 컴퓨터가 2진법(0/1) 데이터를 폰트를 통해 인간이 인식할 수 있는 형태로 글자를 보여 준다면,
OCR은 그 반대로 인간이 종이 위에 써 놓은 글씨를 인지하여 텍스트 데이터로 치환한다.
이게 무슨 말인가 생각을 해봅시다. (하면서 생각해보는데 컴퓨터는 글자를 보여주는 방식은 아직 잘 모르겠습니다.)

OCR이란 위의 그림처럼 인간이 쓴 8 처럼 보이는 글씨를 데이터화 한 후(이때까진 숫자 8인지 컴퓨터는 모른다.), 텍스트 데이터인 8 이라는 숫자로 치환해주는 것이다. (이미지 reference : wikidocs-Pytorch로 시작하는 딥 러닝 입문)
보통은 스캐너로 읽어들인 이미지 파일을 분석하여 텍스트나 워드 파일로 결과물을 내놓는다. Adobe Acrobat도 OCR 기능이 있다. 이미 존재하는 폰트와 대조하는 식으로 이미지를 인식하므로, 적어도 300dpi 이상의 해상도에 필기체보단 정자로 또박또박 잘 쓴 글씨가 인식률이 더 높다. 물론 이전에 프린터로 인쇄했던 문서라면 가장 잘 인식된다. (reference : OCR-나무위키)
검색하다가 네이버(Naver)가 세계 최고 수준의 인식 정확도를 내세울 정도로 OCR 분야에서 앞서 있다는 것을 알게 되었다. 이미 사업을 진행중에 있고, 관련 홈페이지에 process가 소개되어 있다.
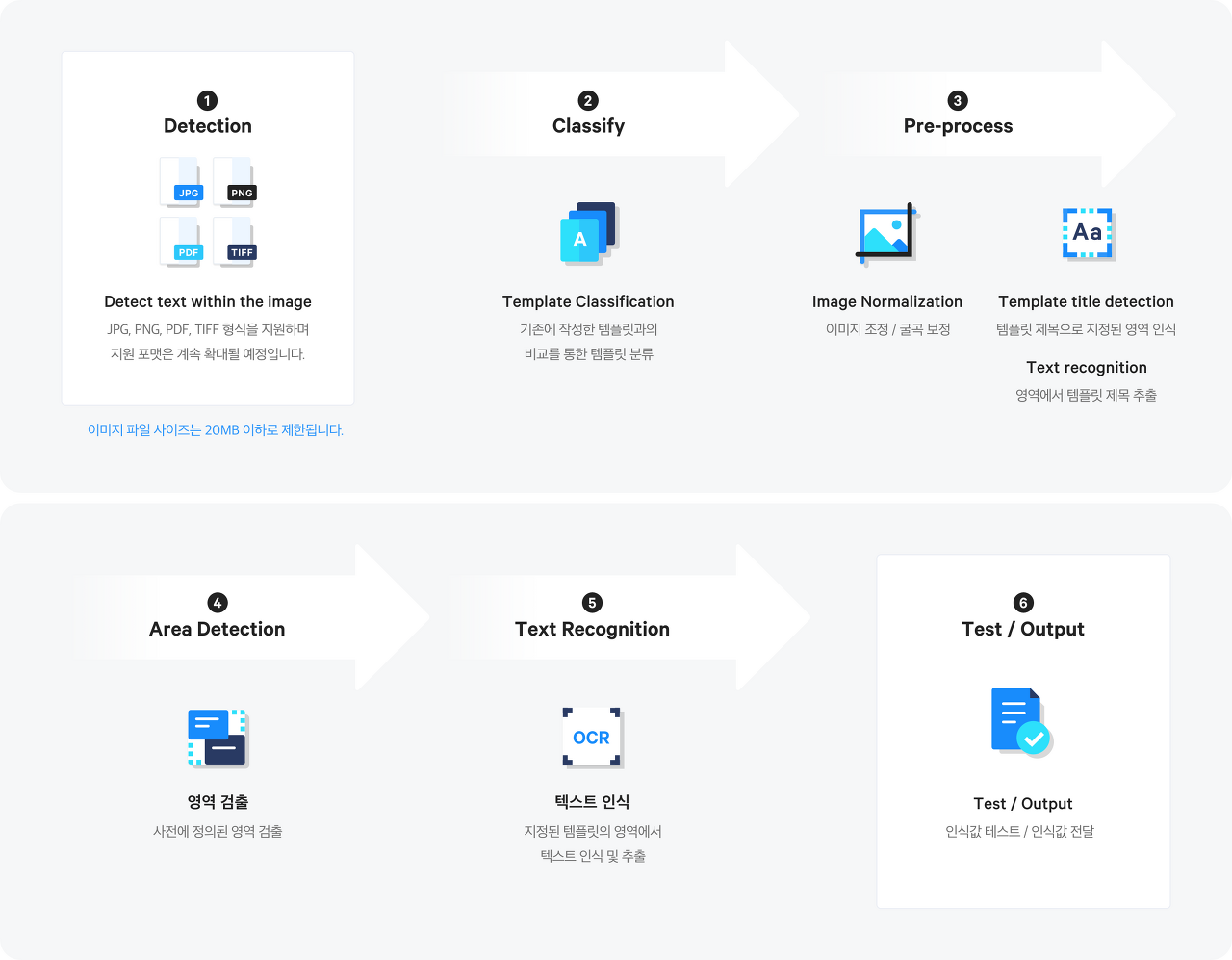
단순한 OCR(광학 문자 인식)을 넘어 문서의 종류를 분류하고, 구조화된 형태로 정확히 문자 정보를 추출합니다.
(reference : 네이버클라우드플랫폼)
즉, 인식를 기반으로 사용자가 업로드한 문서의 종류를 분류하고 원하는 영역에서 텍스트를 인식하고 정보를 추출한다는 것이다.
서론이 길었는데, 그럼 OCR 이라는 기술을 개발하기 위해서는 무엇이 필요한가.
(어떤 것을 만들고 싶은지부터 구체화하고 개발을 진행해야겠지만)
알아보던 중에 딥러닝을 활용한 한글문장 OCR 프로젝트라는 글을 쓱 읽어보게 되었는데, 그리 만만한 기술이 아니구나 싶었다.
다음 글에서는 OCR 구현을 위해 필요한 지식(분야)가 무엇이 있는지 알아보도록 하자.